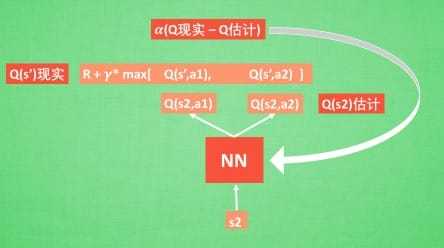
The second modification to online Q-learning aimed at further improving the stability of our method with neural networks is to use a separate network for gen- erating the targets yj in the Q-learning update. More precisely, every C updates we clone the network Q to obtain a target network Q^ and use Q^ for generating the Q-learning targets yj for the following C updates to Q. This modification makes the algorithm more stable compared to standard online Q-learning, where an update that increases Q(st,at) often also increases Q(st 1 1,a) for all a and hence also increases the target yj, possibly leading to oscillations or divergence of the policy. Generating the targets using an older set of parameters adds a delay between the time an update to Q is made and the time the update affects the targets yj, making divergence or oscillations much more unlikely.
if (t > learning_starts and t % learning_freq == 0and replay_buffer.can_sample(batch_size)): # Use the replay buffer to sample a batch of transitions # Note: done_mask[i] is 1 if the next state corresponds to the end of an episode, # in which case there is no Q-value at the next state; at the end of an # episode, only the current state reward contributes to the target obs_batch, act_batch, rew_batch, next_obs_batch, done_mask = replay_buffer.sample(batch_size) # Convert numpy nd_array to torch variables for calculation obs_batch = Variable(torch.from_numpy(obs_batch).type(dtype) / 255.0) act_batch = Variable(torch.from_numpy(act_batch).long()) rew_batch = Variable(torch.from_numpy(rew_batch)) next_obs_batch = Variable(torch.from_numpy(next_obs_batch).type(dtype) / 255.0) not_done_mask = Variable(torch.from_numpy(1 - done_mask)).type(dtype)
if USE_CUDA: act_batch = act_batch.cuda() rew_batch = rew_batch.cuda()
# Compute current Q value, q_func takes only state and output value for every state-action pair # We choose Q based on action taken. current_Q_values = Q(obs_batch).gather(1, act_batch.unsqueeze(1)) # Compute next Q value based on which action gives max Q values # Detach variable from the current graph since we don't want gradients for next Q to propagated next_max_q = target_Q(next_obs_batch).detach().max(1)[0] next_Q_values = not_done_mask * next_max_q # Compute the target of the current Q values target_Q_values = rew_batch + (gamma * next_Q_values) # Compute Bellman error bellman_error = target_Q_values - current_Q_values # clip the bellman error between [-1 , 1] clipped_bellman_error = bellman_error.clamp(-1, 1) # Note: clipped_bellman_delta * -1 will be right gradient d_error = clipped_bellman_error * -1.0 # Clear previous gradients before backward pass optimizer.zero_grad() # run backward pass current_Q_values.backward(d_error.data.unsqueeze(1))
# Perfom the update optimizer.step() num_param_updates += 1
# Periodically update the target network by Q network to target Q network if num_param_updates % target_update_freq == 0: target_Q.load_state_dict(Q.state_dict())
r = 0 ''' for i in reversed(range(steps)): if reward_pool[i] == 0: running_add = 0 else: running_add = running_add * gamma +reward_pool[i] reward_pool[i] = running_add ''' for i inreversed(range(steps)): if reward_pool[i] == 0: r = 0 else: r = r * gamma + reward_pool[i] reward_pool[i] = r
for (log_prob , value), r inzip(save_actions, rewards): reward = r - value.item() policy_loss.append(-log_prob * reward) value_loss.append(F.smooth_l1_loss(value, torch.tensor([r])))
optimizer.zero_grad() loss = torch.stack(policy_loss).sum() + torch.stack(value_loss).sum() loss.backward() optimizer.step()
del model.rewards[:] del model.save_actions[:]
defmain(): running_reward = 10 live_time = [] for i_episode in count(episodes): state = env.reset() for t in count(): action = select_action(state) state, reward, done, info = env.step(action) if render: env.render() model.rewards.append(reward)
if done or t >= 1000: break running_reward = running_reward * 0.99 + t * 0.01 live_time.append(t) plot(live_time) if i_episode % 100 == 0: modelPath = './AC_CartPole_Model/ModelTraing'+str(i_episode)+'Times.pkl' torch.save(model, modelPath) finish_episode()