进程是程序执行时的一个实例,即它是程序已经执行到何种程度的数据结构的汇集;从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的基本单位;
线程是进程的一个执行流,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位;一个进程由几个线程组成(拥有很多相对独立的执行流的用户程序共享应用程序的大部分数据结构),线程与同属一个进程的其他的线程共享进程所拥有的全部资源;
"进程——资源分配的最小单位,线程——程序执行的最小单位"
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响;
头文件:pthread.h,gcc链接时参数:-lpthread;
线程基本函数 int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*func)(void *), void *arg);:创建线程
tid:输出参数,保存返回的线程ID(与linux系统中的线程ID不一样,这个ID应该理解为一个地址),用无符号长整型表示;attr:输入参数,线程的相关属性,如线程优先级、初始栈大小、是否为守护进程等,一般置为NULL,表示使用默认属性;func:输入参数,一个函数指针(void *job(void *arg);),线程执行的函数;arg:输入参数,函数的参数,如果有多个参数须将其封装为一个结构体;返回值:成功返回0,失败返回errno值(正数);
void pthread_exit(void *status);:退出线程
int pthread_join(pthread_t tid, void **status);:等待线程退出
tid:输入参数,指定等待的线程ID;status:输出参数,一个二级指针,保存退出值,可为NULL;返回值:成功返回0,失败返回errno值;
pthread_t pthread_self(void);:获取当前线程ID
int pthread_detach(pthread_t tid);:分离线程
变为分离状态的线程,如果线程退出,它的所有资源将全部释放;
tid:输入参数,指定的线程ID;返回值:成功返回0,失败返回errno值;
线程ID pthread_create()创建的线程;
线程不像进程,一个进程中的线程之间是没有父子之分的,都是平级关系;即线程都是一样的, 退出了一个不会影响另外一个;
但是所谓的主线程main,其入口代码是类似这样的方式调用main的:exit(main(...));
主线程先退出,子线程继续运行的方法:
按照POSIX标准定义,当主线程在子线程终止之前调用pthread_exit()时,子线程是不会退出的;
系统中的线程ID:
ls /proc/[PID]/task/[TID]/:可查看一个进程下的所有线程ID、及相关信息;ps -eo user,pid,ppid,lwp,nlwp,%cpu,%mem,stat,cmd:lwp即线程ID,nlwp为进程中的线程数量;
主线程的线程ID与它所属进程的进程ID相同;
注意:这里的线程ID与pthread_self中的线程ID不是一个概念:gettid获取的是内核中线程ID,而pthread_self获取的是posix描述的线程ID;
在c语言中,可以用syscall(__NR_gettid);(头文件sys/syscall.h)来获取内核中的线程ID;
互斥锁
初始化 static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
mutex:输出参数,互斥变量;attr:输入参数,锁属性,NULL值为默认属性;返回值:成功返回0,失败返回errno值;
加锁、释放锁 int pthread_mutex_lock(pthread_mutex_t *mutex);:加锁(阻塞)
mutex:输入参数,互斥变量;返回值:成功返回0,失败返回errno值;
int pthread_mutex_trylock(pthread_mutex_t *mutex);:尝试加锁(非阻塞)
mutex:输入参数,互斥变量;返回值:成功返回0,锁繁忙返回EBUSY,失败返回errno值;
int pthread_mutex_unlock(pthread_mutex_t *mutex);:释放锁
mutex:输入参数,互斥变量;返回值:成功返回0,失败返回errno值;
销毁 int pthread_mutex_destroy(pthread_mutex_t *mutex);
mutex:输入参数,互斥变量;返回值:成功返回0,失败返回errno值;
条件变量 条件变量是用来等待而不是用来上锁的,条件变量用来自动阻塞一个线程,直到某特殊情况发生为止;通常条件变量和互斥锁同时使用
条件变量使我们可以睡眠等待某种条件出现;条件变量是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待”条件变量的条件成立”而挂起;另一个线程使”条件成立”(给出条件成立信号);
条件的检测是在互斥锁的保护下进行的;如果一个条件为假,一个线程自动阻塞,并释放等待状态改变的互斥锁;
相关函数 int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);:动态初始化int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);:等待条件,阻塞int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex *mutex, const timespec *abstime);:等待条件,超时int pthread_cond_signal(pthread_cond_t *cond);:通知条件,只唤醒单个等待线程int pthread_cond_broadcast(pthread_cond_t *cond);:通知条件,唤醒所有等待线程int pthread_cond_destroy(pthread_cond_t *cond);:销毁
静态初始化、动态初始化(和互斥锁相似):static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;:静态初始化int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);:动态初始化
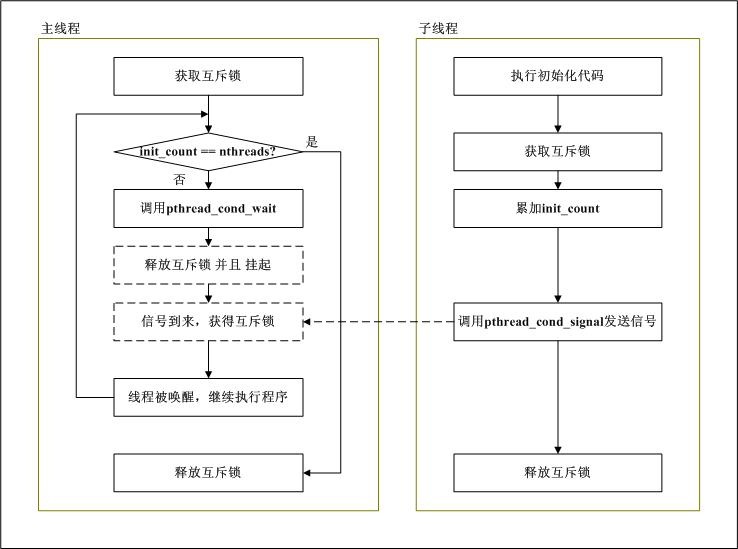
pthread_cond_wait执行流程
传入给pthread_cond_wait的mutex应为一把已经获取的互斥锁;释放互斥锁 并且 将线程挂起(这两个操作是一个原子操作);获得信号,尝试获得互斥锁后被唤醒;
多线程实例
题目
解决
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <unistd.h> #include <sys/types.h> #include <sys/syscall.h> #include <pthread.h> #define gettid() syscall(__NR_gettid) static volatile int flag = 0 ;static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;void *job1 (void *arg) ;void *job2 (void *arg) ;int main (void ) { printf ("++++++++++ entry thread_main (pid: %d, tid: %ld) ++++++++++\n" , getpid(), gettid()); pthread_t tid1, tid2; errno = pthread_create(&tid1, NULL , job1, NULL ); if (errno){ perror("pthread_create" ); exit (EXIT_FAILURE); } errno = pthread_create(&tid2, NULL , job2, NULL ); if (errno){ perror("pthread_create" ); exit (EXIT_FAILURE); } printf ("<thread_main> waiting for 1->2 or 2->1\n" ); errno = pthread_mutex_lock(&mutex); if (errno){ perror("pthread_mutex_lock" ); exit (EXIT_FAILURE); } errno = pthread_cond_wait(&cond, &mutex); if (errno){ perror("pthread_cond_wait" ); exit (EXIT_FAILURE); } errno = pthread_mutex_unlock(&mutex); if (errno){ perror("pthread_mutex_unlock" ); exit (EXIT_FAILURE); } printf ("<thread_main> wait finish\n" ); errno = pthread_join(tid1, NULL ); if (errno){ perror("pthread_join" ); exit (EXIT_FAILURE); } errno = pthread_join(tid2, NULL ); if (errno){ perror("pthread_join" ); exit (EXIT_FAILURE); } errno = pthread_cond_destroy(&cond); if (errno){ perror("pthread_cond_destroy" ); exit (EXIT_FAILURE); } errno = pthread_mutex_destroy(&mutex); if (errno){ perror("pthread_mutex_destroy" ); exit (EXIT_FAILURE); } printf ("---------- leave thread_main (pid: %d, tid: %ld) ----------\n" , getpid(), gettid()); return 0 ; } void *job1 (void *arg) { printf ("++++++++++ entry thread_1 (pid: %d, tid: %ld) ++++++++++\n" , getpid(), gettid()); usleep(500 ); errno = pthread_mutex_lock(&mutex); if (errno){ perror("pthread_mutex_lock" ); exit (EXIT_FAILURE); } printf ("<thread_1> before: %d\n" , flag); if (flag == 2 ){ errno = pthread_cond_signal(&cond); if (errno){ perror("pthread_cond_signal" ); exit (EXIT_FAILURE); } } flag = 1 ; printf ("<thread_1> after: %d\n" , flag); errno = pthread_mutex_unlock(&mutex); if (errno){ perror("pthread_mutex_unlock" ); exit (EXIT_FAILURE); } printf ("---------- leave thread_1 (pid: %d, tid: %ld) ----------\n" , getpid(), gettid()); return NULL ; } void *job2 (void *arg) { printf ("++++++++++ entry thread_2 (pid: %d, tid: %ld) ++++++++++\n" , getpid(), gettid()); usleep(500 ); errno = pthread_mutex_lock(&mutex); if (errno){ perror("pthread_mutex_lock" ); exit (EXIT_FAILURE); } printf ("<thread_2> before: %d\n" , flag); if (flag == 1 ){ errno = pthread_cond_signal(&cond); if (errno){ perror("pthread_cond_signal" ); exit (EXIT_FAILURE); } } flag = 2 ; printf ("<thread_2> after: %d\n" , flag); errno = pthread_mutex_unlock(&mutex); if (errno){ perror("pthread_mutex_unlock" ); exit (EXIT_FAILURE); } printf ("---------- leave thread_2 (pid: %d, tid: %ld) ----------\n" , getpid(), gettid()); return NULL ; } # root @ arch in ~/work on git:master x [13:25:47] $ gcc a.c -lpthread a.c: In function ‘job1’: a.c:79 :18 : warning: unused parameter ‘arg’ [-Wunused-parameter] void *job1 (void *arg) { ^~~ a.c: In function ‘job2’: a.c:111 :18 : warning: unused parameter ‘arg’ [-Wunused-parameter] void *job2 (void *arg) { ^~~ # root @ arch in ~/work on git:master x [13:25:53] $ ./a.out ++++++++++ entry thread_main (pid: 88631 , tid: 88631 ) ++++++++++ ++++++++++ entry thread_1 (pid: 88631 , tid: 88632 ) ++++++++++ <thread_main> waiting for 1->2 or 2->1 ++++++++++ entry thread_2 (pid: 88631 , tid: 88633 ) ++++++++++ <thread_2> before: 0 <thread_2> after: 2 ---------- leave thread_2 (pid: 88631 , tid: 88633 ) ---------- <thread_1> before: 2 <thread_1> after: 1 ---------- leave thread_1 (pid: 88631 , tid: 88632 ) ---------- <thread_main> wait finish ---------- leave thread_main (pid: 88631 , tid: 88631 ) ----------
采用符号常量写出的代码更容易维护;指针常常是边读边移动,而不是边写边移动;许多函数参数是只读不写的。const最常见用途是作为数组的界和switch分情况标号(也可以用枚举符代替)
取代了C中的宏定义,声明时必须进行初始化。const限制了常量的使用方式,并没有描述常量应该如何分配。如果编译器知道了某const的所有使用,它甚至可以不为该const分配空间。最简单的常见情况就是常量的值在编译时已知,而且不需要分配存储。―《C++ Program Language》
使用指针时涉及到两个对象:该指针本身和被它所指的对象。将一个指针的声明用const“预先固定”将使那个对象而不是使这个指针成为常量。要将指针本身而不是被指对象声明为常量,必须使用声明运算符*const。
从右向左读的记忆方式:
cp is a const pointer to char.
pc2 is a pointer to const char.
将函数传入参数声明为const,以指明使用这种参数仅仅是为了效率的原因,而不是想让调用函数能够修改对象的值。同理,将指针参数声明为const,函数将不修改由这个参数所指的对象。
通常修饰指针参数和引用参数:
可以阻止用户修改返回值。返回值也要相应的付给一个常量或常指针。
const对象只能访问const成员函数,而非const对象可以访问任意的成员函数,包括const成员函数;
const对象的成员是不能修改的,而通过指针维护的对象确实可以修改的;
const成员函数不可以修改对象的数据,不管对象是否具有const性质。编译时以是否修改成员数据为依据进行检查。
静态变量作用范围在一个文件内,程序开始时分配空间,结束时释放空间,默认初始化为0,使用时可以改变其值。
静态变量或静态函数只有本文件内的代码才能访问它,它的名字在其它文件中不可见。
如果一局部变量被声明为static,那么将只有唯一的一个静态分配的对象,它被用于在该函数的所有调用中表示这个变量。这个对象将只在执行线程第一次到达它的定义使初始化。
对于局部静态对象,构造函数是在控制线程第一次通过该对象的定义时调用。在程序结束时,局部静态对象的析构函数将按照他们被构造的相反顺序逐一调用,没有规定确切时间。
如果一个变量是类的一部分,但却不是该类的各个对象的一部分,它就被成为是一个static静态成员。一个static成员只有唯一的一份副本,而不像常规的非static成员那样在每个对象里各有一份副本。同理,一个需要访问类成员,而不需要针对特定对象去调用的函数,也被称为一个static成员函数。
类的静态成员函数只能访问类的静态成员(变量或函数)。
extern可以声明其他文件内定义的变量。在一个程序里,一个对象只能定义一次,它可以有多个声明,但类型必须完全一样。如果定义在全局作用域或者名字空间作用域里某一个变量没有初始化,它会被按照默认方式初始化。
将变量或函数声明成外部链接,即该变量或函数名在其它函数中可见。被其修饰的变量(外部变量)是静态分配空间的,即程序开始时分配,结束时释放。
在C++中,还可以指定使用另一语言链接,需要与特定的转换符一起使用。
extern “C” 声明语句
extern “C” { 声明语句块 }
extern 表明该变量在别的地方已经定义过了,在这里要使用那个变量.
类型修正符(type-modifier),限定一个对象可被外部进程(操作系统、硬件或并发进程等)改变。volatile与变量连用,可以让变量被不同的线程访问和修改。声明时语法:
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。下面是
并行设备的硬件寄存器(如:状态寄存器)
一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
多线程应用中被几个任务共享的变量
一个参数既可以是const还可以是volatile吗?解释为什么。
一个指针可以是volatile 吗?解释为什么。
下面的函数有什么错误:
int square(volatile int *ptr){return *ptr * *ptr;}
是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
是的。尽管这并不很常见。一个例子是当一个中断服务子程序修改一个指向一个buffer的指针时。
这段代码有点变态。这段代码的目的是用来返回指针ptr指向值的平方,但是,由于 ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr){ int a,b; a = *ptr; b = *ptr; return a * b;}
定义一个 包含 线程函数的 参数和返回值的 数据结构。
例子如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <pthread.h> #include <stdio.h> typedef struct thread_data { int a; int b; int result; } thread_data; void *myThread (void *arg) { thread_data *tdata=(thread_data *)arg; int a=tdata->a; int b=tdata->b; int result=a+b; tdata->result=result; pthread_exit(NULL ); } int main () { pthread_t tid; thread_data tdata; tdata.a=10 ; tdata.b=32 ; pthread_create(&tid, NULL , myThread, (void *)&tdata); pthread_join(tid, NULL ); printf ("%d + %d = %d\n" , tdata.a, tdata.b, tdata.result); return 0 ; }
用pthread_exit() 返回线程函数的返回值,用pthread_join 来接受 线程函数的返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <pthread.h> #include <stdio.h> int something_worked (void ) { void *p = malloc (10 ); free (p); return p ? 1 : 0 ; } void *myThread (void *result) { if (something_worked()) { ((int )result) = 42 ; pthread_exit(result); } else { pthread_exit(0 ); } } int main () { pthread_t tid; void *status = 0 ; int result; pthread_create(&tid, NULL , myThread, &result); pthread_join(tid, &status); if (status != 0 ) { printf ("%d\n" ,result); } else { printf ("thread failed\n" ); } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <stdio.h> #include <pthread.h> #include <unistd.h> using namespace std ; struct stu { int age; char *name; long long len; }; void *thread2 (void *data) { struct stu *stu1 =struct stu*)data; printf (" age = %d\n name = %s\n len = %lld\n" ,stu1->age, stu1->name, stu1->len); } int main (void ) { pthread_t id2; int ret; struct stu student ; student.age=10 ; student.name="Hello World!" ; student.len = 12345678901111 ; ret=pthread_create(&id2,NULL ,thread2,(void *)&student); if (ret!=0 ){ printf ("Create pthread2 error!\n" ); } pthread_join(id2, NULL ); return 0 ; } 2. 编译 # g++ test.cpp -pthread
1.1 线程创建函数 int pthread_create (pthread_t * restrict tidp , const pthread_attr_t *restrict attr , void *(*start_rtn) (void * ), void *restrict arg );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 说明:创建一个具有指定参数的线程。 形参: tidp 要创建的线程的线程id指针 attr 创建线程时的线程属性 start_rtn 返回值是void 类型的指针函数 arg start_rtn的形参 返回值:若是成功建立线程返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 由restrict 修饰的指针是最初唯一对指针所指向的对象进行存取的方法,仅当第二个指针基于第一个时,才能对对象进行存取 pthread_t 类型定义如下 typedef unsigned long int pthread_t 打印时要使用%lu或%u方式 123456789101112131415161718
1.2 等待线程结束函数 int pthread_join(pthread_t thread, void **retval);
1 2 3 4 5 6 7 8 9 10 说明:这个函数是一个线程阻塞的函数,调用它的函数将一直等待到被等待的线程结束为止,当函数返回时,被等待线程的资源被收回 形参: thread 被等待的线程标识符 retval 一个用户定义的指针,它可以用来存储被等待线程的返回值 返回值:成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
1.3 线程退出函数 void pthread_exit(void *retval);
1 2 3 4 5 6 7 8 9 说明:终止调用它的线程并返回一个指向某个对象的指针 形参: retval 函数的返回指针,只要pthread_join中的第二个参数retval不是NULL ,这个值将被传递给retval 返回值:无 头文件:#include <pthread.h> 123456789
1.4 线程取消函数 int pthread_cancel(pthread_t thread);
1 2 3 4 5 6 7 8 9 说明:取消某个线程的执行 形参: thread 要取消线程的标识符ID 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789
其他说明:一个线程能够被取消并终止执行需要满足两个条件(1) 线程是否可以被取消,默认可以被取消;(2) 线程处于可取消点才能取消,可以设置线程为立即取消 或只能在取消点 被取消。
1.5 设置可取消状态函数 int pthread_setcancelstate (int state, int *oldstate);
1 2 3 4 5 6 7 8 9 10 11 12 说明:设置当前线程的可取消性状态 形参: state 要更新的心状态值 oldstate 原来存储的状态 state的合法值: PTHREAD_CANCEL_DISABLE 针对目标线程的取消请求将处于未决状态,请求未处理但仍然存在,除非该线程修改自己的状态,否则不会被取消 PTHREAD_CANCEL_ENABLE 针对目标线程的取消请求将被传递,此状态为创建线程时的默认状态 返回值:成功返回0 ,否则返回错误编号以指明错误 123456789101112
1.6 设置取消类型函数 int pthread_setcanceltype (int type, int *oldtype);
1 2 3 4 5 6 7 8 9 10 11 12 说明:设置当前线程的取消类型,即设置在接收到取消操作后是立即终止还是在取消点终止 形参: type 为调用线程新的可取消性 oldtype 存储原来的类型 type的合法值如下: PTHREAD_CANCEL_ASYNCHRONOUS 可随时执行新的或未决的取消请求 PTHREAD_CANCEL_DEFERRED 目标线程到达一个取消点之前,取消请求将一直处于未决状态;此类型为创建线程时的默认类型 返回值:成功返回0 ,否则返回错误编号以指明错误 123456789101112
1.7 获取当前线程ID函数 pthread_t pthread_self (void);
1 2 3 4 5 说明:获取当前调用线程的 thread identifier (标识号) 形参:无 返回值:当前线程的线程ID标识 头文件:#include <pthread.h> 12345
1.8 分离释放线程函数 int pthread_detach (pthread_t thread);
1 2 3 4 5 6 7 8 9 说明:线程资源释放方式设置函数 形参: thread 要释放线程的标识符ID 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789
其他说明:linux线程执行和windows不同,pthread有两种状态joinable状态和unjoinable状态。
一个线程默认的状态 是joinable,如果线程是joinable状态,当线程函数自己返回退出时或pthread_exit 时都不会释放线程所占用堆栈和线程描述符(总计8K多),只有当你调用了pthread_join 之后这些资源才会被释放。
若是unjoinable状态的线程,这些资源在线程函数退出时或pthread_exit 时自动会被释放。
unjoinable属性可以在pthread_create时指定,或在线程创建后在线程中pthread_detach自己设置, 如:pthread_detach(pthread_self()),将状态改为unjoinable状态,确保资源的释放。如果线程状态为joinable,需要在之后适时调用pthread_join。
1.9 比较两个线程是否是同一线程 int pthread_equal (pthread_t thread1, pthread_t thread2);
1 2 3 4 5 6 7 8 9 10 说明:判断两个线程ID是否是同一个 形参: thread1 要比较的线程的标识符ID1 thread2 要比较的线程的标识符ID2 返回值:不相等返回0 ,相等非零 头文件:#include <pthread.h> 12345678910
1.10 线程私有数据操作函数 创建线程私有数据
1 2 3 4 5 6 7 8 9 说明:创建线程私有数据TSD,提供线程私有的全局变量。使用同名而不同内存地址的线程私有数据结构 形参: key 线程私有数据 第二个参数 如果第二个参数不为空,在线程退出时将以key所关联数据为参数调用其指向的资源释放函数,以释放分配的缓冲区 其他说明:不论哪个线程调用pthread_key_create()函数,所创建的key都是所有线程可访问的,但各个线程可根据自己的需要往key中填入不同的值 相当于提供了同名不同值的全局变量,各线程对自己私有数据操作互相不影响 123456789
注销线程私有数据
1 2 3 该函数并不检查当前是否有线程正是用该TSD,也不会调用清理函数(destr_function) 将TSD释放以供下一次调用pthread_key_create()使用 123
读写线程私有数据
1 2 3 4 函数pthread_setspecific()将pointer的值(非内容)与key相关联 函数pthread_getspecific()将与key相关联的数据读出来 所有数据都设置为void *,因此可以指向任何类型的数据 1234
2. 线程属性函数 属性对象是不透明的,而且不能通过赋值直接进行修改。系统提供了一组函数,用于初始化、配置和销毁线程属性。
2.1 初始化一个线程对象的属性 int pthread_attr_init (pthread_attr_t *attr);
1 2 3 4 5 6 7 8 9 说明:pthread_attr_init实现时为属性对象分配了动态内存空间 Posix线程中的线程属性pthread_attr_t 主要包括scope属性、detach属性、堆栈地址、堆栈大小、优先级 形参: attr 指向一个线程属性的指针 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789
2.2 销毁一个线程属性对象 int pthread_attr_destroy (pthread_attr_t *attr);
1 2 3 4 5 6 7 8 9 说明:经pthread_attr_destroy去除初始化之后的pthread_attr_t 结构被pthread_create函数调用,将会导致其返回错误 形参: attr 指向一个线程属性的指针 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789
2.3 获取线程分离状态属性 int pthread_attr_getdetachstate (pthread_attr_t *attr, int *detachstate);
1 2 3 4 5 6 7 8 9 10 说明:获取线程分离状态属性;pthread_detach()分离释放线程资源函数 形参: attr 指向一个线程属性的指针 detachstate 保存返回的分离状态属性 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.4 修改线程分离状态属性 int pthread_attr_setdetachstate (pthread_attr_t *attr, int detachstate);
1 2 3 4 5 6 7 8 9 10 11 12 说明:修改线程分离状态属性;pthread_detach()分离释放线程资源函数 形参: attr 指向一个线程属性的指针 detachstate 有两个取值 PTHREAD_CREATE_JOINABLE(可连接),使用attr创建的所有线程处于可连接状态,线程终止不会回收相关资源,需在其他线程调用pthread_detach()或pthread_join()函数 PTHREAD_CREATE_DETACHED(分离),使用attr创建的所有线程处于分离状态,这类线程终止带有此状态的线程相关资源将被系统收回 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789101112
2.5 获取线程间的CPU亲缘性 int pthread_attr_getaffinity_np (pthread_attr_t *attr, size_t cpusetsize, cpu_set_t *cpuset);
1 2 3 4 5 6 7 8 9 10 11 说明:获取线程的CPU亲缘属性 形参: attr 指向一个线程属性的指针 cpusetsize 指向CPU组的缓冲区大小 cpuset 指向CPU组的指针 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 1234567891011
2.6 设置线程的CPU亲缘性 int pthread_attr_setaffinity_np (pthread_attr_t *attr, size_t cpusetsize, const cpu_set_t *cpuset);
1 2 3 4 5 6 7 8 9 10 11 说明:通过指定cupset来设置线程的CPU亲缘性 形参: attr 指向一个线程属性的指针 cpusetsize 指向CPU组的缓冲区大小 cpuset 指向CPU组的指针 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 1234567891011
2.7 获取线程的作用域 int pthread_attr_getscope (pthread_attr_t *attr, int *scope);
1 2 3 4 5 6 7 8 9 10 说明:指定了作用域也就指定了线程与谁竞争资源 形参: attr 指向一个线程属性的指针 scope 返回线程的作用域 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.8 设置线程的作用域 int pthread_attr_setscope (pthread_attr_t *attr, int scope);
1 2 3 4 5 6 7 8 9 10 11 12 说明:指定了作用域也就指定了线程与谁竞争资源 形参: attr 指向一个线程属性的指针 scope 线程的作用域,可以取如下值 PTHREAD_SCOPE_SYSTEM 与系统中所有进程中线程竞争 PTHREAD_SCOPE_PROCESS 与当前进程中的其他线程竞争 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789101112
2.9 获取线程的栈保护区大小 int pthread_attr_getguardsize (pthread_attr_t *attr, size_t *guardsize);
1 2 3 4 5 6 7 8 9 10 说明:获取线程的栈保护区大小 形参: attr 指向一个线程属性的指针 guardsize 返回获取的栈保护区大小 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.10 设置线程的栈保护区大小 int pthread_attr_setguardsize (pthread_attr_t *attr, size_t *guardsize);
1 2 3 4 5 6 7 8 9 10 11 说明:参数提供了对栈指针溢出的保护。默认为系统页大小,如果设置为0 表示没有保护区。 大于0 ,则会为每个使用 attr 创建的线程提供大小至少为 guardsize 字节的溢出保护区 形参: attr 指向一个线程属性的指针 guardsize 线程的栈保护区大小 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 1234567891011
2.11 获取线程的堆栈信息(栈地址和栈大小) int pthread_attr_getstack (pthread_attr_t *attr, void **stackaddr, size_t *stacksize);
1 2 3 4 5 6 7 8 9 10 11 说明:获取线程的堆栈地址和大小 形参: attr 指向一个线程属性的指针 stackaddr 返回获取的栈地址 stacksize 返回获取的栈大小 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 1234567891011
2.12 设置线程的堆栈区 int pthread_attr_setstack (pthread_attr_t *attr, void *stackaddr, size_t stacksize);
1 2 3 4 5 6 7 8 9 10 11 说明:设置堆栈区,将导致pthread_attr_setguardsize失效 形参: attr 指向一个线程属性的指针 stackaddr 线程的堆栈地址:应该是可移植的,对齐页边距的,可以用posix_memalign来进行获取 stacksize 线程的堆栈大小:应该是页大小的整数倍 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 1234567891011
2.13 获取线程堆栈地址 int pthread_attr_getstackaddr (pthread_attr_t *attr, void **stackaddr);
1 2 3 4 5 6 7 8 9 10 说明:函数已过时,一般用pthread_attr_getstack来代替 形参: attr 指向一个线程属性的指针 stackaddr 返回获取的栈地址 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.14 设置线程堆栈地址 int pthread_attr_setstackaddr (pthread_attr_t *attr, void *stackaddr);
1 2 3 4 5 6 7 8 9 10 说明:函数已过时,一般用pthread_attr_setstack来代替 形参: attr 指向一个线程属性的指针 stackaddr 设置线程堆栈地址 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.15 获取线程堆栈大小 int pthread_attr_getstacksize (pthread_attr_t *attr, size_t *stacksize);
1 2 3 4 5 6 7 8 9 10 说明:获取线程堆栈大小 形参: attr 指向一个线程属性的指针 stacksize 返回线程的堆栈大小 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 12345678910
2.16 设置线程堆栈大小 int pthread_attr_setstacksize (pthread_attr_t *attr, size_t stacksize);
1 2 3 4 5 6 7 8 9 10 11 12 说明:设置线程堆栈大小 形参: attr 指向一个线程属性的指针 stacksize 设置线程的堆栈大小,stack 属性的合法值包括 PTHREAD_STACK_MIN 该线程的用户栈大小将使用默认堆栈大小,为某个线程所需最小堆栈大小,但对于所有线程,这个大小可能无法接受 具体指定的大小 使用线程的用户堆栈大小的数值,必须不小于最小堆栈大小PTHREAD_STACK_MIN 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> 123456789101112
2.17 获取线程的调度策略 int pthread_attr_getschedpolicy (pthread_attr_t *attr, int *policy);
1 2 3 4 5 6 7 8 9 10 11 说明:获取线程的调度策略 形参: attr 指向一个线程属性的指针 policy 返回线程的调度策略 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h> 1234567891011
按照如下方法使用sched_get_priority_max ( )和sched_get_priority_min ( ),可以得到优先级的最大值和最小值。
1 2 3 #include <sched.h> int sched_get_priority_max (int policy) ; int sched_get_priority_min (int policy) ; 123
两个函数都以调度策略policy为参数,目的是获得对应调度策略的优先级值,而且都返回调度策略的最大或最小优先级值。
2.18 设置线程的调度策略 int pthread_attr_setschedpolicy (pthread_attr_t *attr, int policy);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 说明:设置线程的调度策略 形参: attr 指向一个线程属性的指针 policy 线程的调度策略,posix指定了3 种调度策略属性: SCHED_FIFO 先入先出策略 SCHED_RR 轮转调度,类似于 FIFO,但加上了时间轮片算法 SCHED_OTHER 系统默认策略 SCHED_OTHER是不支持优先级使用的 SCHED_FIFO和SCHED_RR支持优先级的使用,他们分别为1 和99 ,数值越大优先级越高 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h> 1234567891011121314151617
2.19 获取线程的调度参数 int pthread_attr_getschedparam (pthread_attr_t *attr, struct sched_param *param);
1 2 3 4 5 6 7 8 9 10 11 说明:获取线程的调度参数 形参: attr 指向一个线程属性的指针 param 返回获取的调度参数 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h> 1234567891011
2.20 设置线程的调度参数 int pthread_attr_setschedparam (pthread_attr_t *attr, const struct sched_param *param);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 说明:设置线程的调度参数,用于设置优先级 形参: attr 指向一个线程属性的指针 param 要设置的调度参数,sched_param结构体至少需要定义这个数据成员 struct sched_param { int sched_priority; /* Scheduling priority */ }; sched_param可能还有其他的数据成员,以及多个用来返回和设置最小优先级、最大优先级、调度器、参数等的函数。 如果调度策略是SCHED_FIFO或SCHED_RR,那么要求具有值的唯一成员是sched_priority。 返回值:若是成功返回0,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h> 1234567891011121314151617
2.21 获取线程是否继承调度属性 int pthread_attr_getinheritsched (pthread_attr_t *attr, int *inheritsched);
1 2 3 4 5 6 7 8 9 10 11 说明:获取线程是否继承调度属性 形参: attr 指向一个线程属性的指针 inheritsched 返回继承调度属性的设置 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h> 1234567891011
2.22 设置线程是否继承调度属性 int pthread_attr_setinheritsched (pthread_attr_t *attr, int inheritsched);
1 2 3 4 5 6 7 8 9 10 11 12 13 说明:设置线程是否继承调度属性 形参: attr 指向一个线程属性的指针 inheritsched 设置线程是否继承调度属性,可能取值如下 PTHREAD_INHERIT_SCHED 调度属性将继承于正创建的线程。忽略在 pthread_create() 的attr定义中的调度属性设置 PTHREAD_EXPLICIT_SCHED 调度属性将被设置为pthread_create()的attr中指定的属性值 返回值:若是成功返回0 ,否则返回错误的编号 头文件:#include <pthread.h> #include <sched.h>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <pthread.h> #include <stdio.h> #define NUM_THREADS 5 void *say_hello (void *args) { printf ("Hello Runoob!\n" ); } int main () { pthread_t tids[NUM_THREADS]; for (int i = 0 ; i < NUM_THREADS; ++i) { int ret = pthread_create(&tids[i], NULL , say_hello, NULL ); if (ret != 0 ) { printf ("pthread_create error: error_code = %d\n" , ret); } } pthread_exit(NULL ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <pthread.h> #include <stdio.h> #include <stdlib.h> #define NUM_THREADS 5 void *print_hello (void *threadid) { int tid = *((int *)threadid); printf ("Hello Runoob! 线程 ID, %d\n" , tid); pthread_exit(NULL ); } int main () { pthread_t threads[NUM_THREADS]; int index[NUM_THREADS]; for (int i = 0 ; i < NUM_THREADS; ++i) { printf ("main() : 创建线程, %d\n" , i); index[i] = i; int ret = pthread_create(&threads[i], NULL , print_hello, (void *)&(index[i])); if (ret != 0 ) { printf ("pthread_create error: error_code = %d\n" , ret); exit (-1 ); } } pthread_exit(NULL ); }123456789101112131415161718192021222324252627282930
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <pthread.h> #include <stdio.h> #include <stdlib.h> #define NUM_THREADS 5 struct thread_data { int thread_id; double message; }; void *print_hello (void *threadarg) { struct thread_data *my_data =struct thread_data *) threadarg; printf ("Thread ID : %d\n" , my_data->thread_id); printf ("Message : %f\n" , my_data->message); pthread_exit(NULL ); } int main () { pthread_t threads[NUM_THREADS]; struct thread_data td [NUM_THREADS ]; for (int i = 0 ; i < NUM_THREADS; ++i) { printf ("main() : creating thread, %d\n" , i); td[i].thread_id = i; td[i].message = i; int ret = pthread_create(&threads[i], NULL , print_hello, (void *)&(td[i])); if (ret != 0 ) { printf ("pthread_create error: error_code = %d\n" , ret); exit (-1 ); } } pthread_exit(NULL ); }1234567891011121314151617181920212223242526272829303132333435363738394041
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 main() : creating thread, 0 main() : creating thread, 1 Thread ID : 0 Message : 0.000000 main() : creating thread, 2 Thread ID : 1 main() : creating thread, 3 Message : 1.000000 Thread ID : 2 main() : creating thread, 4 Message : 2.000000 Thread ID : 3 Thread ID : 4 Message : 3.000000 Message : 4.000000
特点:同时创建多个子进程,每个子进程可以执行不同的任务,程序 可读性较好,便于分析,易扩展为多个子进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int main (void ) { printf ("before fork(), pid = %d\n" , getpid()); pid_t p1 = fork(); if ( p1 == 0 ) { printf ("in child 1, pid = %d\n" , getpid()); return 0 ; } pid_t p2 = fork(); if ( p2 == 0 ) { printf ("in child 2, pid = %d\n" , getpid()); return 0 ; Printf("hello world" ); } int st1, st2; waitpid( p1, &st1, 0 ); waitpid( p2, &st2, 0 ); printf ("in parent, child 1 pid = %d\n" , p1); printf ("in parent, child 2 pid = %d\n" , p2); printf ("in parent, pid = %d\n" , getpid()); printf ("in parent, child 1 exited with %d\n" , st1); printf ("in parent, child 2 exited with %d\n" , st2); return 0 ; }
##第二种方法:for 循环方法
特点:其实每次循环只是创建了单个进程,并没有同时创建多个进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <stdio.h> #include <unistd.h> #include <sys/types.h> int main () { printf ("This is parent process%d\n" ,getpid()); pid_t p1,p2; int i; for (i=0 ;i<=2 ;i++) { if ((p1=fork())==0 ) { printf ("This is child_1 process%d\n" ,getpid()); return 0 ; } wait(p1,NULL ,0 ); printf ("This is parent process%d\n" ,getpid()); } }
正确的使用Linux中的用fork()由一个父进程创建同时多个子进程的格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int status,i;for (i = 0 ; i < 10 ; i++){ status = fork(); if (status == 0 || status == -1 ) break ; } if (status == -1 ){ } else if (status == 0 ) { while (1 ); } else { while (1 ); }
fock 的意思是复制进程, 就是把当前的程序再加载一次, 不同之处在,加载后,所有的状态和当前进程是一样的(包括变量)。 fock 不象线程需提供一个函数做为入口, fock后,新进程的入口就在 fock的下一条语句。返回:子进程中为0,父进程中为子进程I D,出错为-1
如果你使用过Linux的命令,那么对于管道这个名词你一定不会感觉到陌生,因为我们通常通过符号”|”来使用管道;
但是管道的真正定义是什么呢?
举个例子,在shell中输入命令:ls -l | grep string
匿名管道pipe int pipe(filedes[2]);:创建一个匿名管道
头文件:unistd.h
filedes[2]:输出参数,用于接收pipe返回的两个文件描述符;filedes[0]读管道、filedes[1]写管道返回值:成功返回0,失败返回-1,并设置errno
匿名管道实质上是一个先进先出(FIFO)的队列:filedes[0]是队头(front),filedes[1]是队尾(rear);
数据从队尾进,从队头出,遵循先进先出的原则;
pipe()创建的管道,其实是一个在内核中的缓冲区,该缓冲区的大小一般为一页,即4K字节;
先来看一个简单的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <unistd.h> int main (int argc, char *argv[]) { if (argc < 3 ){ fprintf (stderr , "usage: %s parent_sendmsg child_sendmsg\n" , argv[0 ]); exit (EXIT_FAILURE); } int pipes[2 ]; if (pipe(pipes) < 0 ){ perror("pipe" ); exit (EXIT_FAILURE); } pid_t pid = fork(); if (pid < 0 ){ perror("fork" ); exit (EXIT_FAILURE); }else if (pid > 0 ){ char buf[BUFSIZ + 1 ]; int nbuf; strcpy (buf, argv[1 ]); write(pipes[1 ], buf, strlen (buf)); sleep(1 ); nbuf = read(pipes[0 ], buf, BUFSIZ); buf[nbuf] = 0 ; printf ("parent_proc(%d) recv_from_child: %s\n" , getpid(), buf); close(pipes[0 ]); close(pipes[1 ]); }else if (pid == 0 ){ char buf[BUFSIZ + 1 ]; int nbuf = read(pipes[0 ], buf, BUFSIZ); buf[nbuf] = 0 ; printf ("child_proc(%d) recv_from_parent: %s\n" , getpid(), buf); strcpy (buf, argv[2 ]); write(pipes[1 ], buf, strlen (buf)); close(pipes[0 ]); close(pipes[1 ]); } return 0 ; }
1 2 3 4 5 6 7 # root @ arch in ~/work on git:master x [14:44:49] $ gcc a.c # root @ arch in ~/work on git:master x [14:44:52] $ ./a.out from_parent from_child child_proc (4335 ) recv_from_parent: from_parentparent_proc (4334 ) recv_from_child: from_child
注意到父进程的sleep(1);语句:filedes[] = {3, 4},即3为队头,4为队尾;
因为实质上在内核中只存在一个管道缓冲区,是父进程创建的,只不过子进程通过fork也拥有了它的引用;
所以,一般是不建议上面这种做法的,通常做法是:
比如这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <unistd.h> int main (int argc, char *argv[]) { if (argc < 3 ){ fprintf (stderr , "usage: %s parent_sendmsg child_sendmsg\n" , argv[0 ]); exit (EXIT_FAILURE); } int pipes1[2 ], pipes2[2 ]; if (pipe(pipes1) < 0 || pipe(pipes2) < 0 ){ perror("pipe" ); exit (EXIT_FAILURE); } pid_t pid = fork(); if (pid < 0 ){ perror("fork" ); exit (EXIT_FAILURE); }else if (pid > 0 ){ close(pipes1[0 ]); close(pipes2[1 ]); char buf[BUFSIZ + 1 ]; strcpy (buf, argv[1 ]); write(pipes1[1 ], buf, strlen (buf)); int nbuf = read(pipes2[0 ], buf, BUFSIZ); buf[nbuf] = 0 ; printf ("parent_proc(%d) recv_msg: %s\n" , getpid(), buf); close(pipes1[1 ]); close(pipes2[0 ]); }else if (pid == 0 ){ close(pipes1[1 ]); close(pipes2[0 ]); char buf[BUFSIZ + 1 ]; int nbuf = read(pipes1[0 ], buf, BUFSIZ); buf[nbuf] = 0 ; printf ("child_proc(%d) recv_msg: %s\n" , getpid(), buf); strcpy (buf, argv[2 ]); write(pipes2[1 ], buf, strlen (buf)); close(pipes1[0 ]); close(pipes2[1 ]); } return 0 ; }
1 2 3 4 5 6 7 # root @ arch in ~/work on git:master x [15:17:04] C:130 $ gcc a.c # root @ arch in ~/work on git:master x [15:17:07] $ ./a.out parent child child_proc (4622 ) recv_msg: parentparent_proc (4621 ) recv_msg: child
默认的阻塞模式
管道读写规则
O_NONBLOCK关闭:read调用阻塞,即进程暂停执行,一直等到有数据来到为止;O_NONBLOCK打开:read调用返回-1,errno值为EAGAIN;
当管道满的时候
O_NONBLOCK关闭:write调用阻塞,直到有进程读走数据;O_NONBLOCK打开:调用返回-1,errno值为EAGAIN;
如果所有管道写端对应的文件描述符被关闭,则read返回0;
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性;
PIPE_BUF的大小为4096字节,注意,这不是管道的缓冲区大小,这个大小和写入的原子性有关;
阻塞模式时且n<PIPE_BUF:写入具有原子性,如果没有足够的空间供n个字节全部写入,则阻塞直到有足够空间将n个字节全部写入管道;
非阻塞模式时且n<PIPE_BUF:写入具有原子性,立即全部成功写入,否则一个都不写入,返回错误;
阻塞模式时且n>PIPE_BUF:不具有原子性,可能中间有其他进程穿插写入,直到将n字节全部写入才返回,否则阻塞等待写入;
非阻塞模式时且n>PIPE_BUF:不具有原子性,如果管道满的,则立即失败,一个都不写入,返回错误,如果不满,则返回写入的字节数,即部分写入,写入时可能有其他进程穿插写入;
设置为非阻塞模式 int flags = fcntl(fd, F_GETFL, 0);fcntl(fd, F_SETFL, flags | O_NONBLOCK);fcntl(fd, F_SETFL, flags & ~O_NONBLOCK);
如果你使用过Linux的命令,那么对于管道这个名词你一定不会感觉到陌生,因为我们通常通过符号“|"来使用管道,但是管理的真正定义是什么呢?管道是一个进程连接数据流到另一个进程的通道,它通常是用作把一个进程的输出通过管道连接到另一个进程的输入。
举个例子,在shell中输入命令:ls -l | grep string,我们知道ls命令(其实也是一个进程)会把当前目录中的文件都列出来,但是它不会直接输出,而是把本来要输出到屏幕上的数据通过管道输出到grep这个进程中,作为grep这个进程的输入,然后这个进程对输入的信息进行筛选,把存在string的信息的字符串(以行为单位)打印在屏幕上。
有静就有动,有开就有关,与此相同,与popen函数相对应的函数是pclose函数,它们的原型如下:
1 2 3 #include <stdio.h> FILE* popen (const char *command, const char *open_mode) ; int pclose (FILE *stream_to_close) ;
poen函数允许一个程序将另一个程序作为新进程来启动,并可以传递数据给它或者通过它接收数据。command是要运行的程序名和相应的参数。open_mode只能是"r(只读)"和"w(只写)"的其中之一。注意,popen函数的返回值是一个FILE类型的指针,而Linux把一切都视为文件,也就是说我们可以使用stdio I/O库中的文件处理函数来对其进行操作。
如果open_mode是"r",主调用程序就可以使用被调用程序的输出,通过函数返回的FILE指针,就可以能过stdio函数(如fread)来读取程序的输出;如果open_mode是"w",主调用程序就可以向被调用程序发送数据,即通过stdio函数(如fwrite)向被调用程序写数据,而被调用程序就可以在自己的标准输入中读取这些数据。
pclose函数用于关闭由popen创建出的关联文件流。pclose只在popen启动的进程结束后才返回,如果调用pclose时被调用进程仍在运行,pclose调用将等待该进程结束。它返回关闭的文件流所在进程的退出码。
很多时候,我们根本就不知道输出数据的长度,为了避免定义一个非常大的数组作为缓冲区,我们可以以块的方式来发送数据,一次读取一个块的数据并发送一个块的数据,直到把所有的数据都发送完。下面的例子就是采用这种方式的数据读取和发送方式。源文件名为popen.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main () { FILE *read_fp = NULL ; FILE *write_fp = NULL ; char buffer[BUFSIZ + 1 ]; int chars_read = 0 ; memset (buffer, '\0' , sizeof (buffer)); read_fp = popen("ls -l" , "r" ); write_fp = popen("grep rwxrwxr-x" , "w" ); if (read_fp && write_fp) { chars_read = fread(buffer, sizeof (char ), BUFSIZ, read_fp); while (chars_read > 0 ) { buffer[chars_read] = '\0' ; fwrite(buffer, sizeof (char ), chars_read, write_fp); chars_read = fread(buffer, sizeof (char ), BUFSIZ, read_fp); } pclose(read_fp); pclose(write_fp); exit (EXIT_SUCCESS); } exit (EXIT_FAILURE); }
从运行结果来看,达到了信息筛选的目的。程序在进程ls中读取数据,再把数据发送到进程grep中进行筛选处理,相当于在shell中直接输入命令:ls -l | grep rwxrwxr-x。
当请求popen调用运行一个程序时,它首先启动shell,即系统中的sh命令,然后将command字符串作为一个参数传递给它。
这样就带来了一个优点和一个缺点。优点是:在Linux中所有的参数扩展都是由shell来完成的。所以在启动程序(command中的命令程序)之前先启动shell来分析命令字符串,也就可以使各种shell扩展(如通配符)在程序启动之前就全部完成,这样我们就可以通过popen启动非常复杂的shell命令。
而它的缺点就是:对于每个popen调用,不仅要启动一个被请求的程序,还要启动一个shell,即每一个popen调用将启动两个进程,从效率和资源的角度看,popen函数的调用比正常方式要慢一些。
如果说popen是一个高级的函数,pipe则是一个底层的调用。与popen函数不同的是,它在两个进程之间传递数据不需要启动一个shell来解释请求命令,同时它还提供对读写数据的更多的控制。
pipe函数的原型如下:
1 2 #include <unistd.h> int pipe (int file_descriptor[2 ]) ;
我们可以看到pipe函数的定义非常特别,该函数在数组中墙上两个新的文件描述符后返回0,如果返回返回-1,并设置errno来说明失败原因。
数组中的两个文件描述符以一种特殊的方式连接起来,数据基于先进先出的原则,写到file_descriptor[1]的所有数据都可以从file_descriptor[0]读回来。由于数据基于先进先出的原则,所以读取的数据和写入的数据是一致的。
2、不要用file_descriptor[0]写数据,也不要用file_descriptor[1]读数据,其行为未定义的,但在有些系统上可能会返回-1表示调用失败。数据只能从file_descriptor[0]中读取,数据也只能写入到file_descriptor[1],不能倒过来。
首先,我们在原先的进程中创建一个管道,然后再调用fork创建一个新的进程,最后通过管道在两个进程之间传递数据。源文件名为pipe.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main () { int data_processed = 0 ; int filedes[2 ]; const char data[] = "Hello pipe!" ; char buffer[BUFSIZ + 1 ]; pid_t pid; memset (buffer, '\0' , sizeof (buffer)); if (pipe(filedes) == 0 ) { pid = fork(); if (pid == -1 ) { fprintf (stderr , "Fork failure" ); exit (EXIT_FAILURE); } if (pid == 0 ) { data_processed = read(filedes[0 ], buffer, BUFSIZ); printf ("Read %d bytes: %s\n" , data_processed, buffer); exit (EXIT_SUCCESS); } else { data_processed = write(filedes[1 ], data, strlen (data)); printf ("Wrote %d bytes: %s\n" , data_processed, data); sleep(2 ); exit (EXIT_SUCCESS); } } exit (EXIT_FAILURE); }
可见,子进程读取了父进程写到filedes[1]中的数据,如果在父进程中没有sleep语句,父进程可能在子进程结束前结束,这样你可能将看到两个输入之间有一个命令提示符分隔。
下面来介绍一种用管道来连接两个进程的更简洁方法,我们可以把文件描述符设置为一个已知值,一般是标准输入0或标准输出1。这样做最大的好处是可以调用标准程序,即那些不需要以文件描述符为参数的程序。
为了完成这个工作,我们还需要两个函数的辅助,它们分别是dup函数或dup2函数,它们的原型如下
1 2 3 #include <unistd.h> int dup (int file_descriptor) ;int dup2 (int file_descriptor_one, int file_descriptor_two) ;
dup调用创建一个新的文件描述符与作为它的参数的那个已有文件描述符指向同一个文件或管道。对于dup函数而言,新的文件描述总是取最小的可用值。而dup2所创建的新文件描述符或者与int file_descriptor_two相同,或者是第一个大于该参数的可用值。所以当我们首先关闭文件描述符0后调用dup,那么新的文件描述符将是数字0.
在下面的例子中,首先打开管道,然后fork一个子进程,然后在子进程中,使标准输入指向读管道,然后关闭子进程中的读管道和写管道,只留下标准输入,最后调用execlp函数来启动一个新的进程od,但是od并不知道它的数据来源是管道还是终端。父进程则相对简单,它首先关闭读管道,然后在写管道中写入数据,再关闭写管道就完成了它的任务。源文件为pipe2.c,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main () { int data_processed = 0 ; int pipes[2 ]; const char data[] = "123" ; pid_t pid; if (pipe(pipes) == 0 ) { pid = fork(); if (pid == -1 ) { fprintf (stderr , "Fork failure!\n" ); exit (EXIT_FAILURE); } if (pid == 0 ) { close(0 ); dup(pipes[0 ]); close(pipes[0 ]); close(pipes[1 ]); execlp("od" , "od" , "-c" , 0 ); exit (EXIT_FAILURE); } else { close(pipes[0 ]); data_processed = write(pipes[1 ], data, strlen (data)); close(pipes[1 ]); printf ("%d - Wrote %d bytes\n" , getpid(), data_processed); } } exit (EXIT_SUCCESS); }
从运行结果中可以看出od进程正确地完成了它的任务,与在shell中直接输入od -c和123的效果一样。
现在有这样一个问题,假如父进程向管道file_pipe[1]写数据,而子进程在管道file_pipe[0]中读取数据,当父进程没有向file_pipe[1]写数据时,子进程则没有数据可读,则子进程会发生什么呢?再者父进程把file_pipe[1]关闭了,子进程又会有什么反应呢?
当写数据的管道没有关闭,而又没有数据可读时,read调用通常会阻塞,但是当写数据的管道关闭时,read调用将会返回0而不是阻塞。注意,这与读取一个无效的文件描述符不同,read一个无效的文件描述符返回-1。
C语言方法一 :http://stackoverflow.com/questions/1510922/waiting-for-all-child-processes-before-parent-resumes-execution-unix
通过不指定pid的方式调用waitpid方法,每次等待一个子进程结束,直到所有子进程都结束(waitpid()返回0)
1 2 3 4 5 while (pid = waitpid(-1 , NULL , 0 )) { if (errno == ECHILD) { break ; } }
C语言方法二 :http://stackoverflow.com/questions/19461744/make-parent-wait-for-all-child-processes
通过调用wait方法,每次等待一个子进程结束,直到所有子进程都结束(wait()返回0)
1 2 3 4 5 6 7 8 9 10 11 pid_t child_pid, wpid;int status = 0 ;for (int id=0 ; id<n; id++) { if ((child_pid = fork()) == 0 ) { exit (0 ); } } while ((wpid = wait(&status)) > 0 );
Python方法 :http://stackoverflow.com/questions/2993487/spawning-and-waiting-for-child-processes-in-python
每创建一个子进程,都将该子进程的pid记录到一个pid的集合中,等所有子进程都创建完毕,逐个wait这个子进程pid集合中的每一个子进程,直到所有子进程都结束
1 2 3 pids.append(subprocess.Popen([RESIZECMD, lot, of, options]) for pid in pids: pid.wait()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/time.h> #define ULLINT unsigned long long #define INPUT 0 #define OUTPUT 1 int main () { struct timeval start ; gettimeofday(&start,NULL ); int file_descriptors[2 ]; int N,M; int cmplen = 0 ; int i=0 ; int returned_count; signal(SIGCHLD, SIG_IGN); FILE *fp = NULL ; char buff[2 ][255 ]; char * Ms, * Ns; fp = fopen("input.txt" , "r+" ); fscanf (fp,"%s" ,buff[0 ]); fscanf (fp,"%s" ,buff[1 ]); Ns = strtok(buff[0 ], "=" ); Ns = strtok(NULL , "=" ); N = atoi(Ns); Ms = strtok(buff[1 ], "=" ); Ms = strtok(NULL , "=" ); M = atoi(Ms); printf ("==> Multi-Process summation program running...\n\n" ); printf ("==> M:%d,N:%d\n" ,M,N); cmplen = M/N; pid_t pid=0 ; pipe(file_descriptors); for (i=0 ;i<N;i++){ if ((pid = fork()) == -1 ) { printf ("Error in fork\n" ); exit (1 ); } if (pid == 0 ) break ; } if (pid == 0 ) { int start_numC,cmplenC,resC; start_numC = i*cmplen+1 ; if (i==N-1 ){ cmplenC = M-cmplen*i; } else { cmplenC = cmplen; } resC = (2 *start_numC+cmplenC-1 )*cmplenC/2 ; printf ("==> Now child process (i:%d) is running, the partly result is: %d\n" ,i,resC); close(file_descriptors[INPUT]); write(file_descriptors[OUTPUT], &resC , sizeof (resC)); exit (0 ); } else { wait(NULL ); int buf=0 ,buf_old=0 ,sum=0 ; printf ("==> Now parent process is running...\n" ); close(file_descriptors[OUTPUT]); while (1 ){ returned_count = (int )read(file_descriptors[INPUT], &buf, sizeof (buf)); if (buf_old==buf){ break ; } sum += buf; printf ("%d bytes of data received from spawned process: %d\n" , returned_count, buf); buf_old = buf; } printf ("\nSum:%d\n" ,sum); FILE *fpo = NULL ; fpo = fopen("output.txt" , "w+" ); fprintf (fpo, "%d" ,sum); } struct timeval end ; gettimeofday(&end, NULL ); ULLINT timer = 1000000 * (end.tv_sec-start.tv_sec)+end.tv_usec-start.tv_usec; printf ("\nTime used: %llu us\n" ,timer); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <pthread.h> #include <sys/time.h> #define ULLINT unsigned long long time_t t_start,t_end;static pthread_mutex_t testlock;int part_res[100 ] = {0 };int M=0 ,N=0 ,cmplen=0 ,sum=0 ;int count=0 ;void partSum () { int start_numC,cmplenC,resC; int i=count; count++; start_numC = i*cmplen+1 ; if (i==N-1 ){ cmplenC = M-cmplen*i; } else { cmplenC = cmplen; } resC = (2 *start_numC+cmplenC-1 )*cmplenC/2 ; printf ("==> Now child process (i:%d) is running, the partly result is: %d\n" ,i,resC); pthread_mutex_lock(&testlock); sum+=resC; pthread_mutex_unlock(&testlock); } int main (int argc, const char * argv[]) { struct timeval start ; gettimeofday(&start,NULL ); int i=0 ; FILE *fp = NULL ; char buff[2 ][255 ]; char * Ms, * Ns; fp = fopen("input.txt" , "r+" ); fscanf (fp,"%s" ,buff[0 ]); fscanf (fp,"%s" ,buff[1 ]); Ns = strtok(buff[0 ], "=" ); Ns = strtok(NULL , "=" ); N = atoi(Ns); Ms = strtok(buff[1 ], "=" ); Ms = strtok(NULL , "=" ); M = atoi(Ms); printf ("==> Multi-Thread summation program running...\n\n" ); printf ("==> M:%d,N:%d\n" ,M,N); cmplen = M/N; pthread_mutex_init(&testlock, NULL ); int ret_thrd[N],ret; pthread_t thread[N]; for (i=0 ;i<N;i++){ ret_thrd[i] = pthread_create(&thread[i], NULL , (void *)&partSum, (void *)NULL ); if (ret_thrd[i] != 0 ) { printf ("==> Thread %d built failed!\n" ,i); } else { printf ("==> Thread %d built successfully!\n" ,i); } } for (i=0 ;i<N;i++){ ret = pthread_join(thread[i], NULL ); } printf ("Sum: %d\n" ,sum); FILE *fpo = NULL ; fpo = fopen("output.txt" , "w+" ); fprintf (fpo, "%d" ,sum); struct timeval end ; gettimeofday(&end, NULL ); ULLINT timer = 1000000 * (end.tv_sec-start.tv_sec)+end.tv_usec-start.tv_usec; printf ("\nTime used: %llu us\n" ,timer); return 0 ; }